
|
Алгоритмы обхода в глубину и по уровням Подобный обход можно совершать двумя различными способами. При обходе в глубину проход по выбранному пути осуществляется настолько глубоко, насколько это возможно, а при обходе по уровням мы равномерно двигаемся вдоль всех возможных направлений. Изучим теперь эти два способа более подробно. В обоих случаях мы выбираем одну из вершин графа в качестве отправной точки. Ниже под "посещением узла" мы понимаем выполнение действия, которое необходимо совершить в каждой вершине. Если, например, идет поиск, то фраза о том, что мы посетили данный узел, означает, что мы проверили его на наличие требуемой информации. Описываемые методы работают без каких-либо изменений как на ориентированных, так и на неориентированных графах. Мы будем иллюстрировать их на неориентированных графах. С помощью любого из этих методов можно проверить, связен ли рассматриваемый граф. При обходе графа можно составить список пройденных узлов, а по завершении обхода составленный список можно сравнить со списком всех узлов графа. Если списки содержат одни и те же элементы, то граф связен. В противном случае в графе есть вершины, до которых нельзя дойти из начальной вершины, поэтому он несвязен. Обход в глубину При обходе в глубину мы посещаем первый узел, а затем идем вдоль ребер графа, пока не упремся в тупик. Узел неориентированного графа является тупиком, если мы уже посетили все примыкающие к нему узлы. В ориентированном графе тупиком также оказывается узел, из которого нет выходящих ребер. После попадания в тупик мы возвращаемся назад вдоль пройденного пути пока не обнаружим вершину, у которой есть еще не посещенный сосед, а затем двигаемся в этом новом направлении. Процесс оказывается завершенным, когда мы вернулись в отправную точку, а все примыкающие к ней вершины уже оказались посещенными. Иллюстрируя этот и другие алгоритмы обхода, при выборе одной из двух вершин мы всегда будем выбирать вершину с меньшей (в числовом или лексикографическом порядке) меткой. При реализации алгоритма выбор будет определяться способом хранения ребер графа. Рассмотрим граф с рис. 1. Начав обход в глубину в вершине 1, мы затем посетим последовательно вершины 2, 3, 4, 7, 5 и 6 и упремся в тупик. Затем нам придется вернуться в вершину 7 и обнаружить, что вершина 8 осталась непосещенной. Однако, перейдя в эту вершину, мы немедленно вновь оказываемся в тупике. Вернувшись в вершину 4, мы обнаруживаем, что непосещенной осталась вершина 9; ее посещение вновь заводит нас в тупик. Мы снова возвращаемся назад в исходную вершину, и поскольку все соседние с ней вершины оказались посещенными, обход закончен. 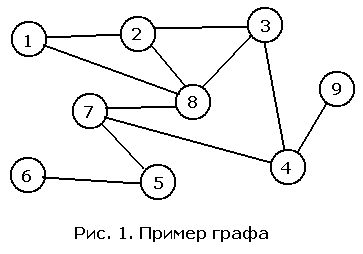
DepthFirstTraversal (G, v) G граф v текущий узел Visit(v) Mark(v) for каждого ребра vw графа G do if вершина w непомечена then DepthFirstTraversal(G, w) end if end forЭтот рекурсивный алгоритм использует системный стек для отслеживания текущей вершины графа, что позволяет правильно осуществить возвращение, наткнувшись на тупик. Вы можете построить аналогичный нерекурсивный алгоритм самостоятельно, воспользовавшись стеком для занесения туда и удаления пройденных вершин графа. Обход по уровням При обходе по уровням мы, после посещения первого узла, посещаем все соседние с ним вершины. При втором проходе посещаются все вершины "на расстоянии двух ребер" от начальной. При каждом новом проходе обходятся вершины, расстояние от которых до начальной на единицу больше предыдущего. В графе могут быть циклы, поэтому не исключено, что одну и ту же вершину можно соединить с начальной двумя различными путями. Мы обойдем эту вершину впервые, дойдя до нее по самому короткому пути, и посещать ее второй раз нет необходимости. Поэтому, чтобы предупредить повторное посещение, нам придется либо вести список посещенных вершин, либо занести в каждой вершине флажок, указывающий, посещали мы ее уже или нет. Вернемся к графу с рис. 4. Начав обход с вершины 1, на первом проходе мы посетим вершины 2 и 8. На втором проходе на нашем пути окажутся вершины 3 и 7. (Вершины 2 и 8 также соединены с исходной вершиной путями длины два, однако мы не вернемся в них, поскольку уже побывали там при первом проходе.) При третьем проходе мы обойдем вершины 4 и 5, а при последнем - вершины 6 и 9. В основе обхода в глубину лежала стековая структура данных, а при обходе по уровням мы воспользуемся очередью. Вот как выглядит алгоритм обхода по уровням: BreadthFirstTraversal(G, v) G граф v текущий узел Visit(v) Mark(v) Enqueue(v) while очередь непуста do Dequeue(x) for каждого ребра xw в графе G do if вершина w непомечена then Visit(w) Mark(w) Enqueue(w) end if end for end whileЭтот алгоритм заносит в очередь корень дерева обхода по уровням, но затем немедленно удаляет его из очереди. При просмотре соседних с корнем вершин он заносит их в очередь. После посещения всех соседних с корнем вершин происходит возвращение к очереди и обращение к первой вершине оттуда. Обратите внимание на то, что поскольку узлы добавляются к концу очереди, ни одна из вершин, находящихся на расстоянии двух ребер от корня, не будет рассмотрена повторно, пока не будут обработаны и удалены из очереди все вершины на расстоянии одного ребра от корня. Анализ алгоритмов обхода При разработке алгоритмов обходы мы стремились к тому, чтобы посещать каждую вершину связного графа в точности один раз. Посмотрим сначала, удалось ли нам этого достичь. При обходе по уровням мы начинали с исходной вершины и шли по всем доступным ребрам, если только вершина на втором конце ребра не оказывалась уже посещенной. Приводит ли это к каким-либо трудностям? Любой из узлов, в который можно попасть из данного, окажется посещенным - но вдоль самого прямого пути. Вернувшись к графу на рис. 1, мы замечаем, что мы не возвращались к узлу 8 после посещения узлов 2 и 3. Однако все те узлы, до которых можно добраться из вершины 8, оказываются посещенными, поскольку мы дошли до этой вершины на более раннем проходе. С другой стороны, может и в связном графе оказаться узел, до которого мы не дошли? Поскольку при каждом проходе мы делаем один шаг от вершин, посещенных на предыдущем проходе, узел может оказаться непосещенным только, если он не является соседом никакого из посещенных узлов. Но это означало бы, что граф несвязен, что противоречит нашему предположению; значит мы посетим все узлы. Аналогичное рассуждение справедливо и для обхода в глубину. В этом случае мы заходим вглубь графа пока не наткнемся на тупик. Посетим ли мы, возвращаясь, все остальные узлы? Может ли так получиться, что в какую-то из вершин графа мы не зайдем? При каждом попадании в тупик мы возвращаемся до первого узла, из которого есть проход к еще не посещенному узлу. Тогда мы следуем этим проходом и снова идем по графу в глубину. Встретив новый тупик, мы вновь возвращаемся назад, пока не наткнемся на первую вершину с еще не посещенным соседом. Чтобы одна из вершин графа осталась непосещенной, нужно, чтобы она не была соседней ни для одной из посещенных вершин. А это и означает, что граф несвязен вопреки наши предположениям. При обходе в глубину мы также должны посетить все узлы. Что можно сказать про эффективность такого алгоритма? Будем предполагать, что основная часть всей работы приходится на посещение узла. Тогда расходы на проверку того, посещали ли мы уже данный узел, и на переход по ребру можно не учитывать. Поэтому порядок сложности алгоритма определяется числом посещений узлов. Как мы уже говорили, каждая вершина посещается в точности один раз, поэтому на графе с N вершинами происходит N посещений. Таким образом, сложность алгоритма равна O(N). |